Immutable Infrastructure - The What and Why
Immutable Infrastructure became the new buzzword of DevOps teams a few years ago (around the time that Cattle Not Pets became the decisive philosophy of those same teams) and is one that makes perfect sense. In order for Infrastructure as Code mentalities to be properly executed we need to think of infrastructures (and in particular Cloud Infrastructure) less as nodes to be manually configured and more as abstract objects which have their configurations and very existence centrally controlled and destroyed as they are needed.

Immutable vs Mutable
Traditional (virtual) infrastructure is typically mutable, Servers, Switches, Firewalls and Storage which are manually created and then manually configured as and when they are needed, leading to the age old problem of configuration drift. How does Exchange Server A stack up against Exchange Server B? What hacks have been employed over it’s lifetime to make it stay upright and more to the point how exactly are they documented? This problem also extends in to the cloud to a worrying degree, with Cloud deployments made manually and without an endgame in sight.
This is just a small scale example, and when (as many of us are) you’re dealing with a fleet of hundreds if not thousands of nodes centralised configuration becomes an urgent matter, otherwise you quickly start relying on the arcane knowledge of a Senior Administrator who isn’t really utilising a latent skill, they just know where the bodies are buried, because they buried them in the first place. Be honest that person has probably been you in the past, it’s certainly been me.
On the surface, Immutable Infrastructure seeks to solve these issues by combining Source Control with both Infrastructure as Code and Configuration Management tooling (my big favourites here are Terraform and Ansible), the intention being that once a definition of your infrastructure is changed in Source Control the components are recreated, leaving the live infrastructure always as a reflection of how you have declared it in source control. This approach is fantastic but requires an incredibly careful hand when considering how you intend to deploy. In a world of ever growing complexity and ever more disposable instances (as MicroServices, Containers and Serverless deployments become more commonplace, we cannot realistically manage these all individually and attempting to do so is a fools errand).
Everything Or Not?
This also raises a bigger question, should everything be immutable or only certain segments of the infrastructure?
I am inclined to say that that as much as possible should be immutable, but there are certain areas that should probably remain mutable.
Consider Storage for example; Containers almost always create with ephemeral storage which is destroyed as soon as the Container reaches the end of it’s life, so we aren’t concerned about that storage, but what about shared storage hosting say your companies primary file shares? They probably don’t want to be reprovisioned wholesale just because you add a new share in a declarative file. Such a move could be disastrous depending on the abstractions you’re working with.
Likewise your NACLs, Routes etc. surrounding your Firewall(s) and Switching; these too may cause significant operational impacts if you go through the process of reprovisioning every time you wish to make a change, if not carefully thought out you could inadvertently remove your own access in the process of deployment.
So enough about what we shouldn’t include, I’m trying to say this is a good thing and unarguably your compute, container and serverless resources all belong here, with their underlying components being delivered from the same or adjacent delivery pipelines wherever possible. Depending on your platform it may even be realistic to include some of your network and storage architecture, it’s just important you know what you’re getting yourself in to.
Configuration Drift - A Problem To Avoid
We mentioned the problem of Configuration Drift earlier, but let’s see how that looks with a bit more of a detailed example and how exactly centralised, immutable management lets us overcome this problem.
We start with three servers SERVER1, SERVER2 and SERVER3, they’re designed to serve the same service, but in our mutable infrastructure small changes will inevitably be made and we see small updates start to drift in:
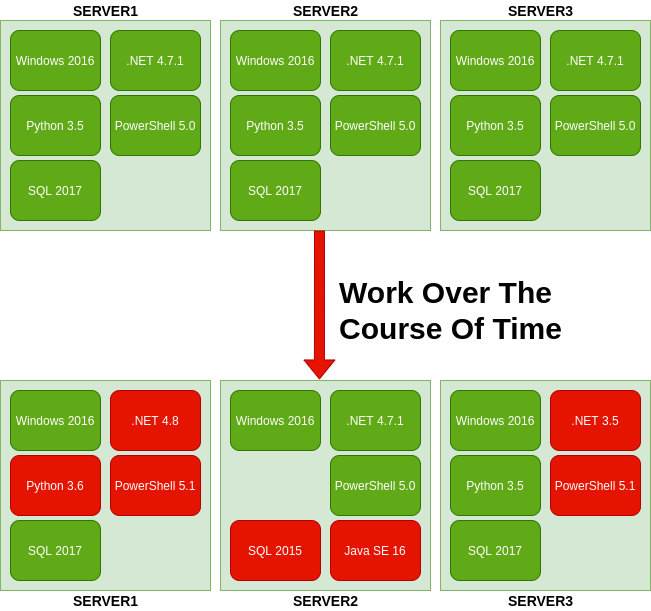
Looking at the inevitable drift on, we see new installs and changes in versions, I’ll wager most people are familiar with this (and will find it in their own environments now) or are guilty of causing such scenarios in the name of getting things working quickly, but it raises the question of how do any of these changes get documented or recorded in any way. In an Immutable Infrastructure such changes cannot occur (or rather they cannot last as they will be undone when a redeployment occurs and as such becomes pointless to engage in).
You may very well ask what does it matter, but I know I’ve spent forever and a day debugging applications only to find out that their issue was caused by incompatible frameworks on the underpinning OS or a misconfiguration that was due to human error in a manual process, again something that immutability and configuration management seek to resolve.
Importing the Existing - An Uphill Battle

Technical Debt is a horror show that we’re all more than familiar with, most IaC tools do have a capacity for importing existing infrastructure for future definition. In the case of Terraform this capacity is there but is still woefully manual (I can hardly complain, the tool is free and it’s incredible), the system is still being actively developed.
If you intend to make your existing infrastructure immutable, you first need to get it under control and ensure that you aren’t trying to control sets of systems that don’t match or line up in the first place, otherwise you’ll just have wildcard systems all over the place. It’s worth the pain to refactor and rebuild in the first instance rather than try and wrangle systems that don’t fit your new model for the rest of time.
Should You Be Doing This?
If you’re attempting to work to a DevOps mentality then almost certainly yes, it allows for configuration control and avoids drift, as well as speeding up the deployment and re-deployment of infrastructure. If you aren’t working to a DevOps mentality, this is one of the aims and might be the time to start thinking about why these tools exist and what they can do for you.
If you’re in the cloud, any cloud, this is the way to maintain order and avoid unstoppable sprawl, a term I always love is “stop it growing arms and legs”. Deploying stable Service Oriented Architecture and maintaining stable delivery pipelines is virtually impossible unless you have a solid foundation, and Immutable Infrastructure is the way to achieve this goal.
Just don’t rush in and decide it’s all or nothing, few things in IT need to be that black and white. There is room, despite what the purists say, for an approach to accommodate an immutable infrastructure for only the components which really need it.