Elastic Kubernetes Service - Automating Secure Role Configuration with Terraform and Vault
UPDATED 11/2020: Have a look at a different method for this configuration better suited to CI/CD.
In a previous post we looked at how to use Terraform provision and authenticate with Clusters using AWS’ Elastic Kubernetes Service (EKS) using the somewhat unique authentication method of it’s webhook token method leveraging aws-iam-authenticator. Once we get past that point however we still have another permission hurdle to overcome, specifically how we handle Users and Roles as defined within the Cluster, and just like with all the EKS permissions we’ve encountered so far…these ones have another bunch of oddities. Let’s jump in to how we can not only get the provisioning automated, but keep our ARNs secret by leveraging Hashicorp Vault.

What, More Permissions?
Following the previous post our Cluster is created and we can interact with it from an administrative standpoint without issue, so what’s going on.
When we create the Cluster using our Terraform Service Account, this account is implicitly defined as the Creator of the Cluster, and as such has full admin permissions, however if we try and interact with the Cluster using kubectl using an account which has matching permissions in AWS IAM, we will be denied access, so what’s going on?
EKS employs a Kubernetes ConfigMap named aws-auth to control administrative access to the Cluster, if we take a look at the current state of this file using kubectl we can see that there are no permissions set for any users:
kubectl -n kube-system get configmap aws-auth -o yaml
# apiVersion: v1
# data:
# api_host: https://<CLUSTER_UID>.sk1.eu-west-1.eks.amazonaws.com
# mapRoles: |
# - groups:
# - system:bootstrappers
# - system:nodes
# rolearn: <NODEGROUP_ROLE_ARN>
# username: system:node:
# kind: ConfigMap
# metadata:
# creationTimestamp: "<LAST_CONFIG_WRITE>"
# name: aws-auth
# namespace: kube-system
# resourceVersion: <VERSION_ID>
# selfLink: /api/v1/namespaces/kube-system/configmaps/aws-auth
# uid: <UID>
What we can see from the output is that a mapping is being made from the NodeGroup ARN used to create the Cluster to the EC2 instances which make up the Cluster’s Worker Nodes.
Out ultimate aim here is to not only maintain this configuration, but to extend it by adding a new YAML list named mapUsers which will map ARNs for users which exist in our IAM (and then optionally add those entries to new entries in our mapRoles list, though we’re not going to look at that just yet).
Terraform for Permission Management
Since we’re creating the entire environment programatically, we don’t want to create the cluster only to set up the permissions manually, let’s get the whole thing working so it can be run in an automation pipeline.
The below main.tf looks at how we can permission our Cluster with a single user with master permissions to the cluster (this is the highest level of access to Kubernetes):
#--main.tf
#--Apply aws-auth configmap
resource "kubernetes_config_map" "aws_auth" {
metadata {
name = "aws-auth"
namespace = "kube-system"
}
data = {
api_host = https://<CLUSTER_UID>.sk1.eu-west-1.eks.amazonaws.com
mapRoles = file("aws_role_config.yaml")
mapUsers = file("aws_user_config.yaml")
}
}
In this example, we would need to have two local YAML files to ingest, structured as below:
#--aws_role_config.yaml
- groups:
- system:bootstrappers
- system:nodes
rolearn: <NODEGROUP_ROLE_ARN>
username: system:node:{{EC2PrivateDNSName}}
#--aws_user_config.yaml
- userarn: <USER_ARN>
username: <USERNAME>
groups:
- system:masters
This configuration presents us with a problem so we won’t be using it. The problem is that we’re looking up the YAML from a plain text file, and this leads us to needing to store both the username for any user(s) we wish to grant access to, as well as the ARNs of our users and the NodeGroup Role ARN.
Clearly, we don’t want to go down this route as this data could very well be considered secret and shouldn’t really be committed to Source Control, so what other options do we have?
ARNs Are Secret - Let’s Make Sure We’re Secure
In order to reliably template this data at run time, we can ingest it as an EOT operation using a YAML filter, whilst this isn’t as nice to read, it does allow us to use the native Vault Provider and allow us to lookup secrets offered by Vault directly in to Terraform (I’ve covered the how to’s on this topic in much greater detail here so I won’t get bogged down in the details).
In Vault we have a kv type Secrets Engine named kv and a Secret in there name aws_secrets, this secret contains 3 Key Value Pairs named nodegroup_arn, user_arn and username, not great for production use but perfect for our example:
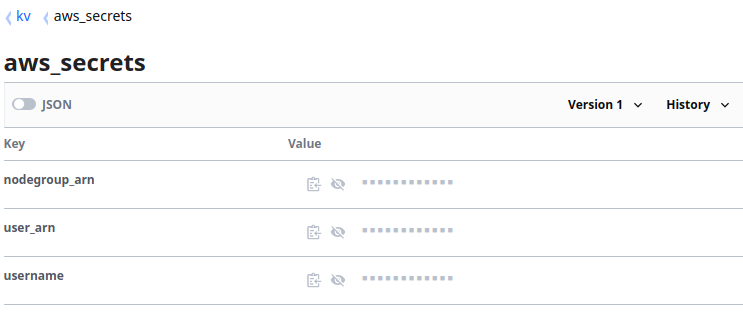
If we look at the below main.tf, we can see the secrets being loaded in using vault resources as well as the YAML data being loaded using an EOT operation:
#--main.tf
#--Secret Lookups
data "vault_generic_secret" "tinfoil" {
path = "kv/aws_secrets"
}
#--Apply aws-auth configmap
resource "kubernetes_config_map" "tinfoil" {
metadata {
name = "aws-auth"
namespace = "kube-system"
}
data = {
api_host = https://<CLUSTER_UID>.sk1.eu-west-1.eks.amazonaws.com
mapRoles =<<YAML
- groups:
- system:bootstrappers
- system:nodes
rolearn: ${data.vault_generic_secret.aws_secrets.data["nodegroup_arn"]}
username: system:node:{{EC2PrivateDNSName}}
YAML
mapUsers =<<YAML
- userarn: ${data.vault_generic_secret.aws_secrets.data["user_arn"]}
username: ${data.vault_generic_secret.aws_secrets.data["username"]}
groups:
- system:masters
YAML
}
}
A few things to be aware of here:
- The configMap is DECLARATIVE, so you still have to define your system values that were there when the cluster was created, removing this from the file is really going to mess up the configuration and stop most functions of the cluster from working!
- Lines 2-4: We’re using the vault_generic_secret Data Source to lookup our aws_secrets Secret via the Vault API (this required the Vault provider to be pre-configured as detailed here).
- Lines 14 and 21: The «YAML function is used to directly inject YAML via terminal input to the mapRoles and mapUsers keys rather than using a flat file.
- Lines 20 and 26 the YAML statement ends the «YAML input.
- Lines 18, 22 and 23: The nodegroup_arn, user_arn and username child values are looked up via the aws_secrets Secrets we looked up on Line 3, preventing us from needing to expose them in the configuration.
…and even with this, it won’t work. There’s something major we still need to get right.
Terraform Importing - Read Before You Write
If we try and execute the main.tf above it will complete it’s plan without issue, but once we try and run we’ll see an error:
terraform apply
# ...
# ...
# Error: configmaps "aws-auth" already exists
Well, yes, it does exist, we’re trying to update it. A bit of tinkering with kubectl confirms that the file can indeed be edited, what’s going on.
The kubernetes_config_map resource has a couple of limitations that need to be understood before you can get anywhere with it, and the notes that break this down are unfortunately limited to the GitHub changelog and don’t seem to have made in in to the official documentatio*.
By default, the resource is read only by default if you’re using EKS Managed Nodes, but Managed Nodes offer us a lot of perks, this seems like a big trade off. The solution when using Managed Nodes is to first import the state of the configMap in to Terraform’s State File, this will allow terraform to master this data and treat the configMap as read/write.
We can do this with a single command:
# In the below we are looking up the "tinfoil" kubernetes_config_map resource
# and defining the namespace "kube-system" with a configMap of "aws-auth"
terraform import kubernetes_config_map.tinfoil kube-system/aws-auth
This command only needs to be issued once (additional attempts will fail cleanly as the resource has already been imported). Finally, our main.tf will configure permissions reliably.
Carriage Returns - A Closing Comment
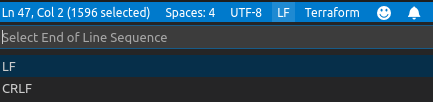
One final point, if you’re using Windows avoid yourself hours of agony by ensuring that your Newline/End Of Line Sequence for your HCL files containing YAML (or your pure YAML files, whichever method your choose to use), are saved as LF (Line Feed) and NOT CRLF (Carriage Return, Line Feed) otherwise you’ll be in a horrific mess when your YAML gets loaded to Kubernetes thanks to the horror of strange escape characters appearing in your data (random \r\n or \r appearing in your YAML) and eating the syntax.
If like me you’re a VSCode user don’t spend an age trying to work out the problem, change the setting by clicking the bottom toolbar and selecting LF when offered the choice and then saving your file:
If you have a burning desire to understand the ins and outs of the history of End of Line Sequences, may I direct you to this StackOverflow post, if you enjoy that kind of thing :)