Infrastructure as Code - Multi-Environment Continuous Deployment with Terraform and BitBucket
Terraform is a powerful Infrastructure as Code tool ideal for creating cloud environments and its flexible HCL syntax allows for the provisioning of complex environments from simple templates, saving countless hours. Often missed is the ability to template resources and use them in conjunction with Terraform’s workspaces feature to maintain concurrent versions of the same environment.
When coupled with even a basic Continuous Deployment pipeline this combination of systems allows for an automated method of maintaining the state of multiple concurrent environments of entire cloud infrastructures. In this article I want to look at how to achieve this configuration, managing multiple AWS environments with a GitFlow methodology using the CD Pipelines functionality provided free in BitBucket.
NOTE: The configurations for this article can be found in my GitHub at here.

The Aim
So let’s be clear, what are we trying to achieve, exactly? We need to be able to…
- Configure all cloud resources in a declarative nature using Terraform.
- Maintain the state of multiple concurrent versions of the same environment, let’s call them dev, test and prod) and ensure that the components of these environments are easily identifiable with tags.
- Have the ability to create further environments to the same specification.
- Ensure that any changes to environments are reflected immediately, or as soon as is realistically possible, in the real world.
- Ensure that we can access our EC2 Instances and S3 Buckets publicly, this deployment will not leverage a Site to Site VPN and will be CLOUD ONLY.
Doesn’t sound too hard does it.
So let’s take a look at what our environment needs to look like:
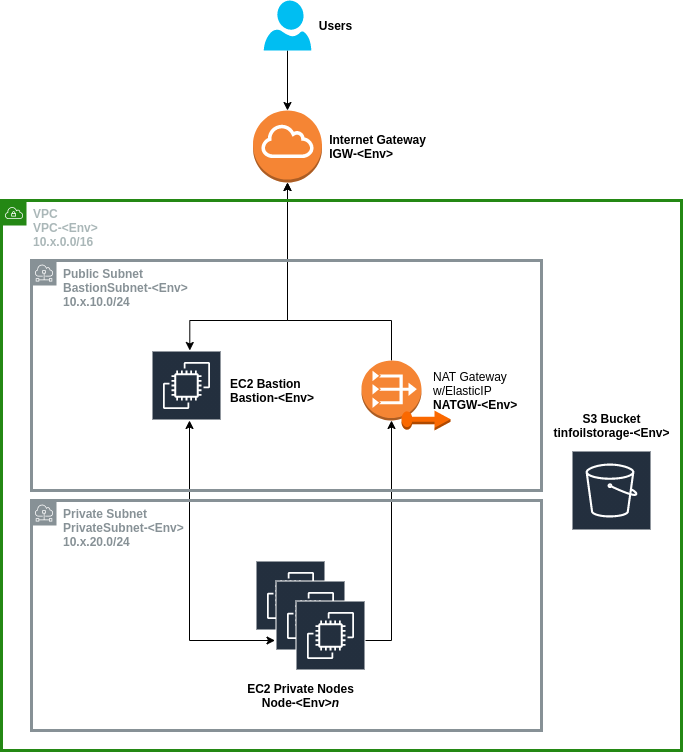
Nothing too complicated going on there; private compute nodes, some object storage and a simple network to allow access from the internet via a Bastion Host. This is going to be the specification for all of our environments.
Terraform isn’t going to worry about configuring the nodes, installing software or configuring the databases (that’s not really Terraform’s job and you shouldn’t try and force it), Ansible is a better bet but we’ll get to configuration in another post.
Security Matters
For the sake of brevity I’m not going to include the details of S3 Bucket Policies or Security Group and NACL configurations in this article, but that doesn’t mean they aren’t important (they’re in the git repo if you want to see them). Since we’re making anything publicly available we need to think carefully about security.
If we look a little closer at our requirements, we’ll need to think about locking up our network. Under the microscope; the security of our VPC is going to look a little more like this:
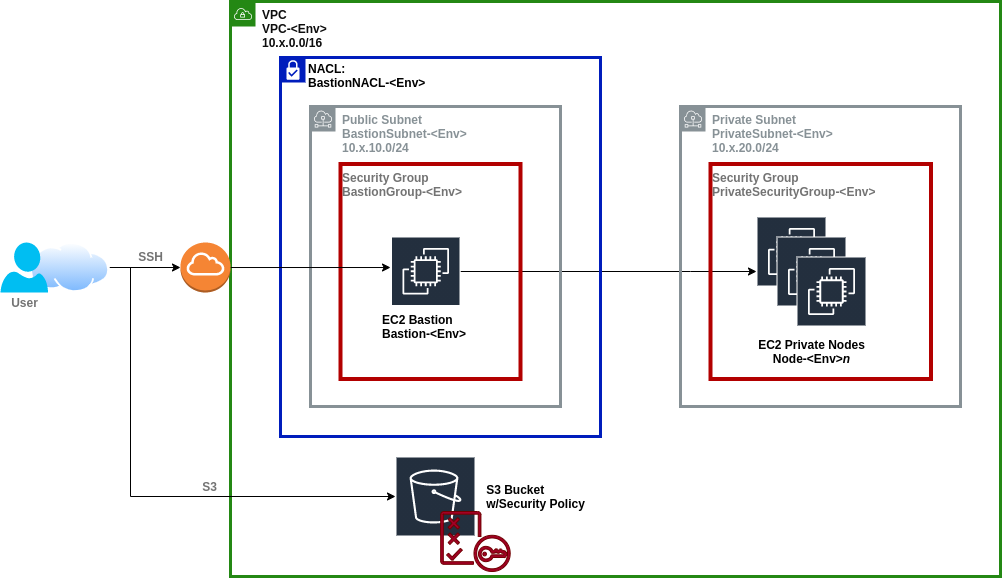
What we’re doing here is controlling access to our VPC as to only allow SSH traffic from our WAN IP (as captured in the wan_edge_ip variable. This will be defined in the NACL and Security Group surrounding the Bastion Subnet and Bastion Host to ensure that the only public ingress that can reach our Bastion Host is from us.
Secondly, the Security Group surrounding the Private Subnet has been configured to allow SSH ingress only from the Bastion Subnet, as it is not public facing and exists within a private network, this means the only way to reach it now is by first accessing our Bastion Host from the WAN IP we have specified.
S3 is controlled by it’s own policy and access is restricted to using the S3 protocol from our WAN IP. We could secure this further by restricting access from the Bastion Host however we’re going to allow access publicly to allow direct console access. As the access list is explicit we will also allow access from our NAT Gateway and from Bitbucket’s range of build agent IPs (without these we won’t be able to manage S3 going forward).
What Will We Need?
There’s a couple of things we’ll need before hand and I’m going to assume they’re all set up, if not I’ve written about most of them before.
- A Terraform binary, I’ll be working with v14.5 (though later is now available), using a fixed version is important as states are not backwards compatible and features do get deprecated.
- An Access Key and Secret Access Key for a suitably permissioned AWS IAM account to allow Terraform to authenticate with AWS.
- An existing SSH key to use for deployments (we’ll just use one over all environments called tinfoilkey).
- A properly configured Terraform backend using S3 and DynamoDB.
- A free BitBucket account with a repository initialised using git.
The Terraform Code
So now that we know what we want, let’s take a look at some simple Terraform code to get up and running.
We’ll be breaking our Terraform configuration down in to a few files, one per segment of the configuration, the whole lot will make for a pretty boring read so I’ve linked out the git repo here, the rough breakdown is
- Network Components (vpc.tf)
- Security Configurations (security.tf)
- Object Storage (s3.tf)
- Compute Instances (ec2.tf)
…and we’ll keep our usual main.tf, and variables.tf to make out base configurations and variable declarations.
Some configurations worth looking at however. Let’s take a look at the main.tf first:
#--Terraform Configuration
terraform {
backend "s3" {
bucket = "tinfoil-terraform-backend"
key = "ec2.tfstate"
region = "eu-west-2"
dynamodb_table = "tinfoil_tf_state_locking"
}
required_providers {
aws = {
source = "hashicorp/aws"
version = "= 3.27"
}
}
}
#--AMI Lookup
data "aws_ami" "tinfoil_ubuntu" {
most_recent = true
filter {
name = "name"
values = ["ubuntu//assets/2021-02-16-infrastructure-as-code-multi-environment-continuous-deployment-with-terraform-and-bitbucket/hvm-ssd/ubuntu-bionic-18.04-amd64-server-*"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["099720109477"] # Canonical
}
Here we’re configuring our backend to look at S3 for state management and we’ll be plugging in to DynamoDB for state locking as we’ve covered previously.
Next we’re configuring our single provider for AWS, note that we aren’t passing any variables but we will be needing them as we’ll see in a second. We are however configuring our providers using the required_providers configuration, as of Terraform v14 this is now the only supported method to pass provider versions (and versions matter!)
Finally we’re using a simple lookup filter to find the latest AMI for Ubuntu 18.04 which will be the image for our EC2 instances.
The below shows the provisioning our EC2 nodes (both our private subnet and our bastion host), we can see that the AMI data source has been looked up, and we are using the count meta-argument to make as many private nodes as we have defined in the private_ec2_nodes variable.
resource "aws_instance" "tinfoil_bastion" {
ami = data.aws_ami.tinfoil_ubuntu.id
instance_type = "t2.micro"
key_name = "tinfoilkey"
subnet_id = aws_subnet.tinfoil_bastion.id
vpc_security_group_ids = [aws_security_group.tinfoil_bastion.id]
tags = {
Name = "Bastion-${var.environment_name}"
Environment = var.environment_name
}
}
resource "aws_instance" "tinfoil_private" {
count = var.private_ec2_nodes
ami = data.aws_ami.tinfoil_ubuntu.id
instance_type = "t2.micro"
key_name = "tinfoilkey"
subnet_id = aws_subnet.tinfoil_private.id
vpc_security_group_ids = [aws_security_group.tinfoil_private.id]
tags = {
Name = "Node-${var.environment_name}${count.index}"
Environment = var.environment_name
}
}
Thinking About Variables
Let’s take a look at our variables.tf:
#--Input Params
variable "environment_name" {
type = string
description = "Environment Name"
}
variable "vpc_address_space" {
type = string
description = "VPC Address Space (CIDR Format)"
}
variable "bastion_cidr" {
type = string
description = "Bastion Subnet Address Space (CIDR Format)"
}
variable "private_cidr" {
type = string
description = "Private Subnet Address Space (CIDR Format)"
}
variable "wan_edge_ip" {
type = string
description = "Developer Office IP"
}
variable "private_ec2_nodes" {
type = number
description = "Amount of private EC2 nodes to provision"
}
All we have here are variable declarations, no definitions are being made. Due to the requirement of working with multiple environments we need to be able to work with multiple copies of the same code and inject in only our variables.
To this end, we can include any amount of .auto.tfvars file which will include variable definitions and will be read in lexical order, for our purposes we only need one which we’ll call environment.auto.tfvars, we can configure all of our environments just using these 6 values:
environment_name = "dev"
vpc_address_space = "10.1.0.0/16"
bastion_cidr = "10.1.10.0/24"
private_cidr = "10.1.20.0/24"
wan_edge_ip = "77.106.154.170/32"
private_ec2_nodes = 3
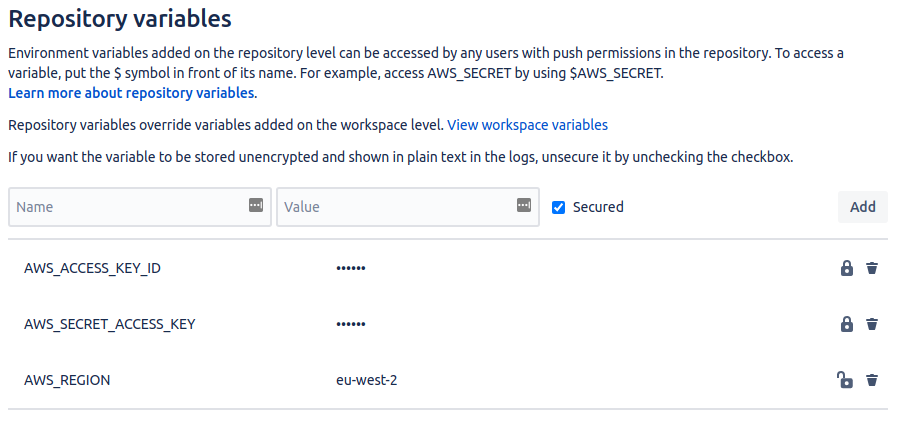
Some Environment Variables will also need to be defined in our BitBucket Pipelines in order to ensure that our configuration can work:
- AWS_ACCESS_KEY_ID - AWS Access Key for a suitably permissioned IAM Account
- AWS_SECRET_ACCESS_KEY - AWS Secret Access Key for a suitably permissioned IAM Account
- AWS_REGION - AWS Default Region
What About Multiple Environments?
OK, so we have the code, but we can’t just apply the same configuration with 3 variable files can we? No, not really, that’s going to cause some problems with your state file. Terraform is going to get pretty confused when you want to call the same resources 3 different things with 3 different sets of configurations.
This is where we can leverage Terraform’s workspace functionality which allows for concurrent versions of the same environment by managing each one via a separate state file.
We’re going to be working with workspaces named for each of our environments (dev, test and prod), to create these we simply need to run:
terraform init
terraform workspace new dev
terraform workspace new test
terraform workspace new prod
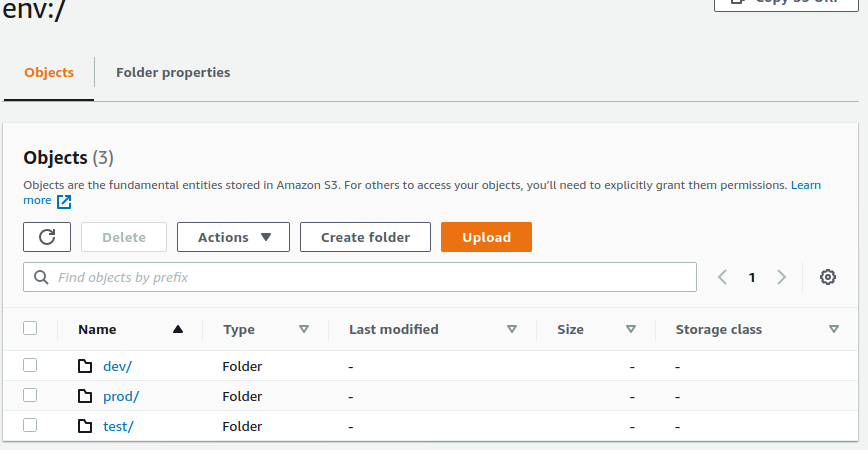
Looking at our S3 backend Bucket we can see that a new env:/ prefix has been created and 3 new prefixes have been created for each of our environments. These will contain our states once we provision environments.
Enabling Continuous Deployment
OK, now we have everything in order, we can build our environments. In order to manage multiple environments in a single repository we’ll be managing the Terraform configurations on individual branches (one-per environment), again named for their functions (dev, test and prod):
We’ll be configuring our branches to each include the same bitbucket-pipelines.yml manifest which contains the instructions on how our Continuous Deployment pipeline will run. The enforcement of the same environment names over all systems allows us to use the $BITBUCKET_BRANCH variable to lookup our Terraform workspace and be sure we will match the correct state file.
As there should always be a workspace and state for each environment, it is therefore safe to use a wildcard to select which branches to run our Terraform steps on:
pipelines:
branches:
'*':
- step:
name: Apply Latest Configuration
image: hashicorp/terraform:0.14.5
script:
- terraform init -backend-config="access_key=$TF_VAR_AWS_ACCESS_KEY" -backend-config="secret_key=$TF_VAR_AWS_SECRET_KEY"
- terraform workspace select $BITBUCKET_BRANCH ||terraform workspace new $BITBUCKET_BRANCH
- terraform validate
- terraform plan -out output.plan
- terraform apply -input=false -auto-approve output.plan
In a nutshell, on commit or merge to any branch, Terraform will be initiated using the S3 backend, a workspace selected (or created if one does not exist using the II operator), the configuration linted, planned to project the desired outcome and then applied without user input.
On each branch, the values within our environment.auto.tfvars will need to differ to reflect the desired values within each of our environment.
Once everything is in place, we can enable Pipelines within our repository:
Provisioning - Does It Work?
From here we can manually run our pipeline against each of our branches to initially provision each of our environments:
The deployment pipeline should now launch and begin the provisioning:
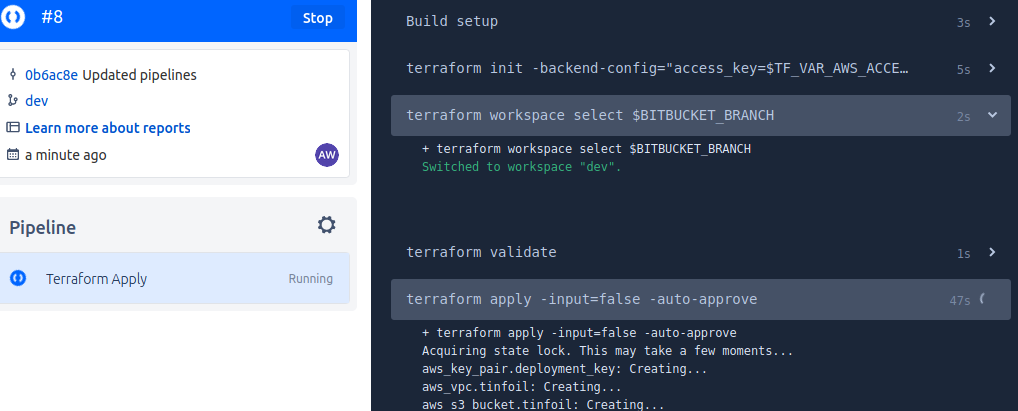
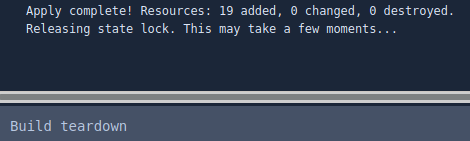
After a provisioning is complete, the State Lock is released and the build is torn down:
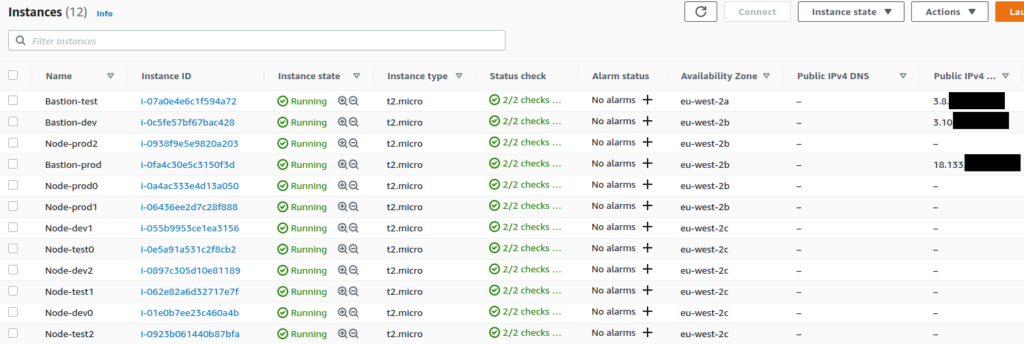
After running against the other branches, we have a complete environment provisioned to AWS:

The rest has been created but let’s not get bored to death with screenshots, you can apply the Terraform config yourself.
Conclusion
We now have 3 fully segregated environments running inside our AWS account, powered by a GitFlow Continuous Deployment pipeline and the route to getting there wasn’t too difficult. Obviously in the real world we’d probably be wanting to deploy to different accounts and that doesn’t really add much more complexity.
Whilst this solution is efficient and effective it’s not the whole story and not without some gotchas which I’ll probably be looking at in future articles, specifically around efficient configuration management over multiple environments and avoiding potential disasters with unintended changes.