Ansible and Google Compute Engine - Building Dynamic Inventories
Recently I’ve been working with Ansible in GCP to try and automate the process of provisioning a bare metal Kubernetes cluster. A good find in this process was the Ansible gcp_compute plugin which allows for the construction of Dynamic Inventories based on your existing GCE resources.

What Are We Working With?
As is often the case with Ansible, the documentation is great but can be confusing without context or to the newcomer. So let’s take a look at how the plugin works and what we’re working with.
I’ve already created an infrastructure within GCE containing several VM Instances which we’re going to look up using the gcp_compute plugin:
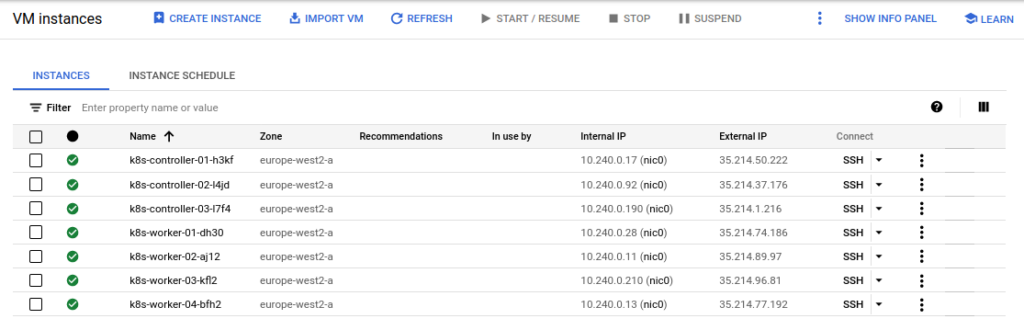
In order for Ansible to communicate with these nodes at the Operating System level at all we’ll need to be able to connect to them via SSH and to do that we’ll first need to learn their IP addresses. Our first issue will occur in an automation environment when we find ourselves unable to learn the IP addresses of something that was just created by another tool.
In the age of cloud environments I’ve found that it’s ill-advised to try and work with a static inventory, especially when your nodes could be transparently replaced at any time and we’re working with DHCP by default. This is where we need to start thinking about Dynamic Inventories that read the state of our environments as they presently are rather than trying to manage a cumbersome list of hosts and IPs. This is easily achieved by authenticating with the GCE API and returning our data.
Configuring the gcp_compute Plugin
Before using the plugin we need to install the google.cloud collection from Ansible Galaxy as well as a prerequisite python package google-auth:
#--Install Google Cloud Ansible Collection
sudo ansible-galaxy collection install google.cloud
#--Install Google Auth Python Package
sudo pip install google-auth
With these installed we can configure an Inventory file to use in our project:
#--gcp_inventory.yaml
plugin: gcp_compute
projects:
- tinfoilproject
regions:
- europe-west2
hostnames:
- public_ip
groups:
controllers: "'controller' in name"
workers: "'worker' in name"
auth_kind: serviceaccount
service_account_file: /tmp/gcp_service_account_file.json
We already have a suitably permissioned Service Account JSON file which will be used to authenticate with GCP (see here for further information on setting this up).
In terms of configuration we’ve added a couple of groups to the inventory to split out our instances in to controllers and workers and defined that our Ansible hostnames will be returned as the Public IP of the VM Instances.
Validating and Using the Inventory
Now we can use the ansible-inventory command to see how our inventory looks and confirm that we are promperly authenticating:
sudo ansible-inventory -i gcp_inventory.yaml --graph
@all:
|--@controllers:
| |--35.214.1.216
| |--35.214.37.176
| |--35.214.50.222
|--@ungrouped:
|--@workers:
| |--35.214.74.186
| |--35.214.77.192
| |--35.214.89.97
| |--35.214.96.81
These IP addresses can now be used as hosts and the groups can now be implicitly called in any Playbooks utilising this Dynamic Inventory at run time.
We can edit the Inventory further to suit our needs for different network configurations by change the hostnames value to either private_ip or hostname:
#--Using private_ip
sudo ansible-inventory -i gcp_inventory.yaml --graph
@all:
|--@controllers:
| |--10.240.0.17
| |--10.240.0.190
| |--10.240.0.92
|--@ungrouped:
|--@workers:
| |--10.240.0.11
| |--10.240.0.13
| |--10.240.0.210
| |--10.240.0.28
#--Using name
sudo ansible-inventory -i gcp_inventory.yaml --graph
@all:
|--@controllers:
| |--k8s-controller-01-h3kf
| |--k8s-controller-02-l4jd
| |--k8s-controller-03-l7f4
|--@ungrouped:
|--@workers:
| |--k8s-worker-01-dh30
| |--k8s-worker-02-aj12
| |--k8s-worker-03-kfl2
| |--k8s-worker-04-bfh2
From here can use this inventory in conjunction with any playbooks using the ansible-playbook
#--Run a playbook using the GCP Inventory
sudo ansible-playbook -i gcp_inventory some_playbook.yaml
#--Run a playbook using a subset of the GCP Inventory (just the "worker" hosts)
sudo ansible-playbook -i gcp_inventory --limit workers some_playbook.yaml
From here any playbooks should be trivial to run against the infrastructure from a centralised Ansible control node or CI/CD pipeline, provided the appropriate network configurations are in place.