Previously I’ve looked at Azure DevOps as a fantastic platform for deploying CI/CD pipelines, and it is, however it’s obvious inclination for Azure makes it something of an issue when trying to work on other public cloud providers, and Azure obviously isn’t the only game in town. There’s also the issue of complexity. Whilst Azure DevOps is incredibly flexible and powerful, this leads to complexity and we don’t always need this level of power for some of our functions. To this end I’ve been working with BitBucket as a means for controlling immutable infrastructure using Terraform, with AWS as our Cloud platform (though we could just as easily work in Azure or GCP).
The simple sample code for this article can be found here.

Some Preamble and Assumptions
BitBucket provides version control using git (as all the best providers do) and release pipelines in YAML using a number of language release agents using lightweight docker instances which are incredibly flexible to work with.
I’m working with a single BitBucket Project named tinfoilcipher and within a single repo named aws, the contents of which are going to be to deliver a simple immutable AWS EC2 environment.
I also have the following configurations in place, ahead of time:
- A pre-created S3 bucket named tinfoilterraformbackend which has been changed from the defaults to include both S3 Object Versioning and AES-256 S3 Encryption
- An SSH keypair named tinfoil-key has already been created (as part of a Terraform file in a different repo)
- Security rules granting access to the EC2 infrastructure are also created from a different repo via Terraform.
Getting Started
Within my aws repo, we have 3 files, which will control the creation and modification of our EC2 instances, as usual these are main.tf, variables.tf and provider.tf:
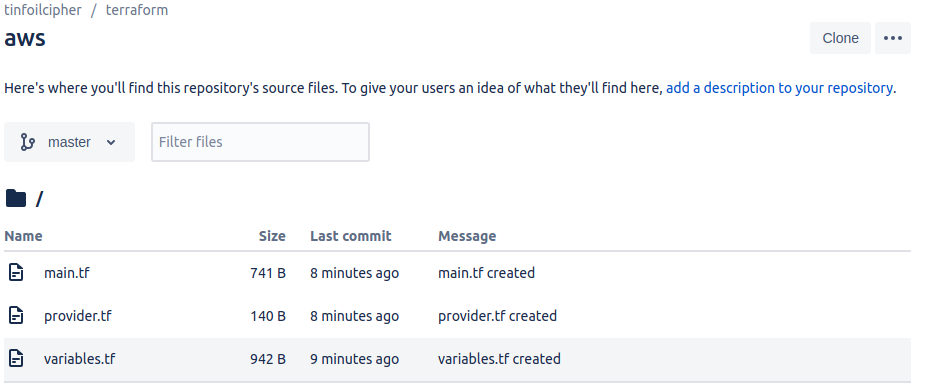
The code content of these files is as below:
#--main.tf
#--BACKEND CONFIG
terraform {
backend "s3" {
bucket = "tinfoilterraformbackend"
key = "terraform.tfstate"
region = "eu-west-2"
}
}
#--PROVISIONING
data "aws_ami" "tinfoil" {
most_recent = true
filter {
name = "name"
values = ["ubuntu/images/hvm-ssd/ubuntu-xenial-16.04-amd64-server-*"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["099720109477"] # Canonical
}
resource "aws_instance" "tinfoil" {
count = length(var.no_instances)
ami = data.aws_ami.tinfoil.id
instance_type = "t2.micro"
key_name = "tinfoil-key"
subnet_id = "subnet-02beca82af6553e64"
count = var.no_instances
tags = {
Name = "instance-${count.index}"
}
}Take note here that we are defining the backend configuration which we will use to centralise states as we have discussed previously. The requirement for this is strict and we will look at this later.
#--varibles.tf
variable "region" {
type = string
description = "Primary Location"
default = "eu-west-2"
}
variable "no_instances" {
type = number
description = "Number of EC2 Instances"
default = 2
}#--provider.tf
provider "aws" {
region = var.region
}Environment Variable – Injection
The initial problem is that we now need to get some secrets in to the pipeline before Terraform is fully loaded (specifically our AWS Access Key ID and Secret Access Key), in order to get around this we can load them as environment variables for the repository within BitBucket and mark them as secret.
We’ll be loading 2 variables and using them for AWS Authentication using the widely supported names of AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY.
Within the repo, we can browse to Repository Settings > Repository Variables and define our variables, ensuring that they are marked as secret:

At runtime, these variables will be injected from the shell in order to expose them to Terraform, we’ll see how they’re injected later.
Configuring a Deployment
Now that our repo is in place, we can configure a Deployment. We’re asked to create a Deployment Template if we try and access the Pipelines tab now and we’ll be asked to set up a Template from some default examples:
There is no default template here for Terraform, however we can construct any Deployment using any Dockerhub image that we know exists, since there are a number of Terraform Images available, we’ll work with the full image.
In order to create a Deployment manually, we need just add a bitbucket-pipelines.yml file to the root of the repo, in this example we’ll be using a repo as below:
pipelines:
branches:
master:
- step:
image: hashicorp/terraform:full
script:
- terraform init -backend-config="access_key=$AWS_ACCESS_KEY_ID" -backend-config="secret_key=$AWS_SECRET_ACCESS_KEY"
- terraform validate
- terraform plan
- terraform apply -input=false -auto-approveA few things to be aware of here:
- We’re defining master under the branches list, meaning that when a change in made to any files in the master branch, a pipeline will be spawed against this deployment.
- The terraform init command is being run with two additional -backend-config arguments, which define the access_key and secret_key variables as Environment Variables from BitBucket, these will be injected in to the Backend Configuration at the head of main.tf and used to authenticate with the S3 Bucket being used as the remote backend.
- The terraform apply command is being run, suppressing inputs and automatically approving changes
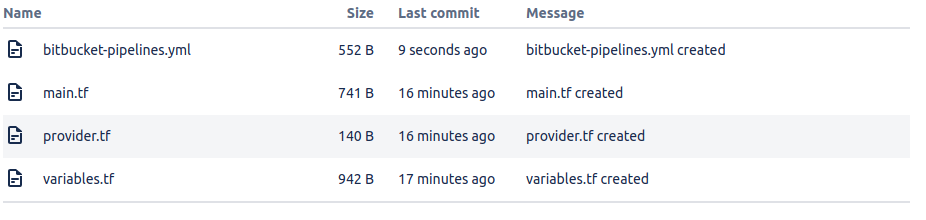
Enabling Pipeines and First Deployment
Creating bitbucket-pipelines.yml gives us a map for our Pipeline to work from, however we still need to enable Pipelines, we can do this from Repository Settings > Settings > Pipeline Settings and enabling Pipelines.
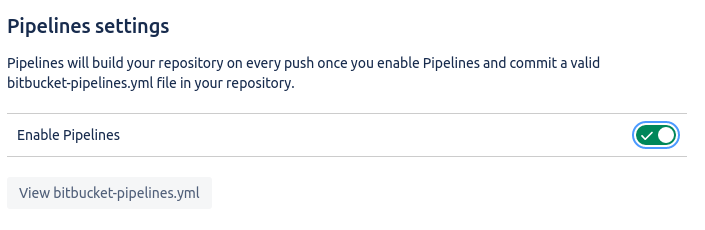
Once we do this with a bitbucket-pipelines.yml file in place, a pipeline is spawned and will run through a series of steps as defined in the YAML file:
- A docker image is pulled and a container created to use as a build agent
- Terraform is initialised with init, including the backend using injected Environment Variables
- The Terraform config is validated using validate
- The Terraform config is planned using plan (whilst this is not too helpful in a non-interactive shell, it can help debug in case of failures)
- The Terraform config is applied using apply, using injected Environment Variables, optional input is suppressed and auto-confirm is approved
- The container is destroyed
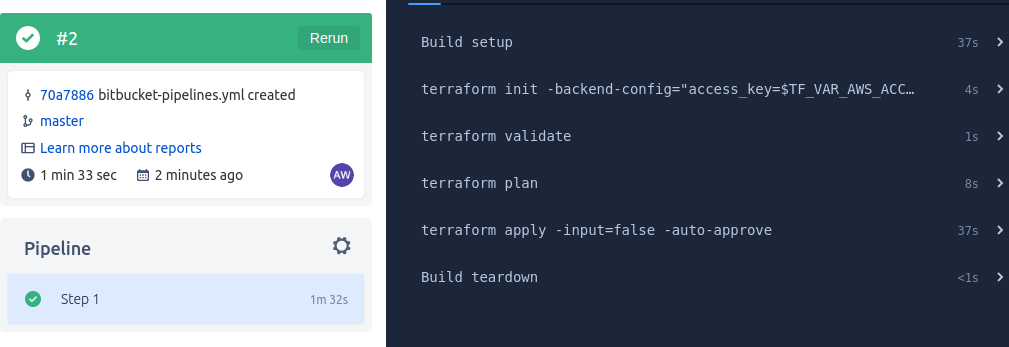
As the variables were marked as secret, they will not appear in the shell in plaintext.
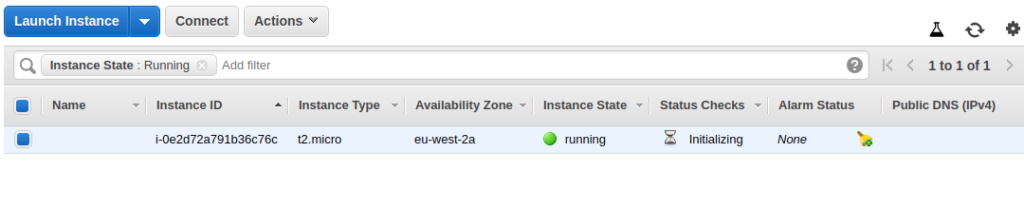
If we now go in to the EC2 console, we can see that one EC2 instance has indeed been created and is initialising:
Remote Backend – Now More Than Ever
A remote backend is critical to automated deployments. Whilst they are always preferable for centralised work, we cannot realistically work without them here.
If we consider how the build is going to work, we have a container performing all of our terraform actions which is using ephemeral storage, as soon as the build process is over the container and it’s storage are going to be destroyed, so this isn’t a safe place for our states to live.
For any automated build we need to work with a remote backend, however we have the issue of needing to authenticate with S3 as part of the backend stanza. To overcome this we authenticate using the access_key and secret_key variables during terraform init by calling the Environment Variables we defined earlier:
#--Extract from bitbucket-pipelines.yml terraform init -backend-config="access_key=$TF_VAR_AWS_ACCESS_KEY" -backend-config="secret_key=$TF_VAR_AWS_SECRET_KEY"
See the Terraform Documentation for further details on passing a Partial Backend Configuration in this manner.
When we look in to our S3 bucket following the first terraform apply action, we can see that the state we indeed generated correctly:

Immutable Infrastructure – Changing the Repo
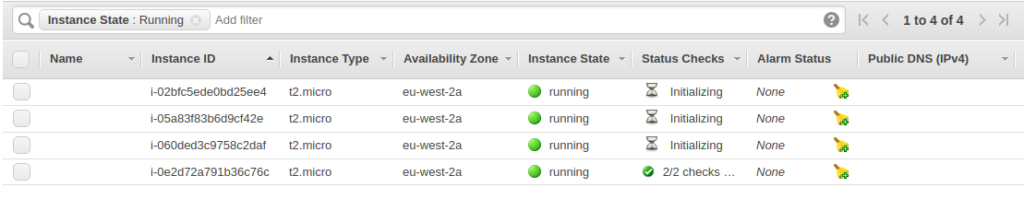
Now we need to sure that our infrastructure is indeed immutable, that changes defined in the repository will always be declarative of the live environment. So let’s change a single line in the main.tf, setting the count value from 1 to 4. This should indicate that a file changed in the master branch, spawn a new pipeline and deploy new instances to AWS.
As soon as the file is changes, a new pipeline is indeed spawned:

If we look at the Shell Output from the terraform apply action we can see that the change that 3 instance were added:

Returning to the EC2 console, we can see that there now 4 instances deployed, the new 3 in the process of initialising:
This is obviously a very simple example just to give a flavour of how this tooling can be applied to AWS. In Part 2 we’ll extend these concepts and take a look at how to introduce Configuration Management to the pipeline with Ansible.